There was no avoiding the buzz surrounding SAP’s recent announcements and demonstration of its newly available in-memory database technology at the SAPPHIRE 2010 conference. There’s a good description of Hasso Plattner’s vision here, and some deep and relevant commentary from Dennis Moore here. Having read previously that SAP acquired Sybase in part to gain access to its in-memory database technology, I was somewhat surprised to see a demonstration of what many are now calling “HassoDB,” which I can only assume is distinctly not Sybase…makes me wonder whether there will be an internal competition between these two platforms. Hasso has been working on the HassoDB for a number of years and even had a keynote on in-memory technology at SAPPHIRE in 2009. I can’t see him giving this up without a fight. With multiple applications already in production leveraging HassoDB (BWA, etc.), where would Sybase fit? Oh yes, I remember now…mobile computing…or was it buying revenue and improving SAP’s earnings per share? I’m just musing…forgive me.
As most who closely follow SAP know, SAP has been talking about in-memory databases for several years. To those that don’t follow the exciting world of database technology, you might even think SAP invented in-memory databases! The truth is that in-memory databases have been around for longer than most realize. Check out this Wikipedia page and you’ll get a sense for the dozens of innovators that led the way well before SAP stepped onto the field. While you won’t see Kinaxis technology mentioned in the mix, we’ve been at it for longer than most—perhaps even the longest. Despite our laser-like focus in this area, our senior architects continue to admit there’s still room for improvement and are in tireless pursuit of it. However, to borrow from the barber’s famous line from one of my favorite Leone spaghetti westerns (“My Name is Nobody”) – they would also state -- Faster than ‘us’, Nobody!
While I wasn’t present to witness it, our development of in-memory technology began 25 years ago with a hand full of brilliant engineers in a basement who founded their own company, Cadence Computer. Their goal was simple: to invent something meaningful and technologically amazing. One of our Chief Architects, Jim Crozman, had an idea to run ERP in-memory—motivated by improving upon a then 30-plus hour run. As you might imagine, finding a machine to run the software that was in his head at that time proved to be impossible, so Jim, along with a small group of talented engineers, did the only thing they could think to do: They invented and constructed a specialized computer (the size of two refrigerators), which would become a dedicated in-memory database appliance—likely a world first. They would call it SP1018. We all know how technologists love a good acronym with some numbers attached to it! At that time, 4MB of RAM took an 8x10 circuit card—and wasn’t cheap! They were packaged into modules with a custom bit slice MRP processing engine capable of 10M instructions per second that could process data in memory at its peak speed. Program and temporary working memory were in their own storage blocks, so the main memory space and bandwidth was reserved for the database. Up to 16 of those processing/memory modules were clustered with a high speed backbone to form single MIMD processing system that could do an MRP “what-if” simulation for a large dataset in minutes. We would go on to sell this computer to GE, at that time an IBM 3090 showcase center. The IBM 3090 had a whopping 192MB of RAM, and sitting next to it, our appliance with 384MB of RAM. IBM’s ERP analytics ran in over three hours, while our appliance replicated the same analytics in approximately three minutes. Computer architecture and speed has evolved greatly since those trailblazing days. Inexpensive multi-core systems with big on-chip caches are capable of tens of billions of instructions per second. No need for custom hardware today! Speaking of on-chip caches, understanding and leveraging this resource has become the key to maximizing speed and throughput. Memory architecture remains 10 times slower than processor speed, so understanding how machines retrieve data and the treatment of that data within the core is fundamental to in-memory database design. It takes the same amount of time to retrieve 1 byte of data as it does 1 block of data. This makes locality of reference a very important system design criteria, minimizing memory access cycles to get the data you need for processing. Data organization and keeping data in a compact form (e.g. eliminating duplication) and with optimal direct relationships and clustering makes for optimal processing speed (minimize memory access cycles). At this year’s SAPPHIRE Conference, SAP explained how it has chosen a hybrid row/column orientation as the construct to store in-memory relational data. Indeed, columnar orientation helps with data locality and compaction of a column of data (obvious), and is most effective in circumstances where the use cases are driven by querying and reporting against a database that does not change or grow rapidly or often. Dennis Moore says it best in his recent blog:
“There are many limitations to a columnar main-memory database when used in update-intensive applications. Many SAP applications are update-intensive. There are techniques that can be used to make a hybrid database combining columnar approach for reading with a row-oriented approach for updates, using a synchronization method to move data from row to column, but that introduces latency between writing and reading, plus it requires a lot of CPU and memory to support the hybrid approach and all the processing between them.”
The challenges associated with columnar orientation will be felt most when attempting to drive performance of complex in-memory analytics. By analytics, I don’t mean complicated SQL statements, compound or otherwise. Rather, I refer to compute-intensive specialized functions, like ATP/CTP, netting, etc. That is calculating consequence to input events based upon a model of the business, particularly the supply chain. Columnar organization solves issues for a small subset of problems but makes most usages of the data much worse. Processing usually involves a significant subset of the fields on a small related set of records at a time. Since a single record's data is spread across different areas of memory by a columnar organization, it causes a bottleneck between memory->cache->processor. A single processor cache line ends up with a single piece of useful information and multiple cache lines are then needed to get just one record's data. For example, ATP for a single order needs a subset of demand, supply, order policies, constraints, BOMs, allocations, inventory, etc. Perhaps this is the main reason why the PhD students at the Hasso Plattner Institute of Design at Stanford reported only achieving a 10x improvement for their ATP analytic prototype using HassoDB, significantly slower than their raw query performance ratios. Millisecond query results are at most half of the equation—and definitely the easiest half. Don’t get me wrong, faster BI reports are great. If you’ve been waiting a few minutes for a report, and you can now get it in seconds, that’s real value. The trick is to go beyond “what is” and “what was” analysis, and add “what will be if” analysis. If done correctly, in-memory analytics can achieve astounding speeds as well. For example, the Kinaxis in-memory engine processes analytics (e.g. ATP), from a standing start (worst-case scenario) with datasets consisting of 1 million part records, generating 2 million planned order recommendations following the creation and processing of 27 million dependent demand records in 37 seconds, while handicapping the processor to a single core. Further, eight different users can simultaneously request the same complete calculations on eight what-if scenarios of the data and still get their independent answers in less than 60 seconds. No need for ”version copy commands.” My personal favorite performance test done in our labs involves proving that the more users logged into to the system, the less time it takes for them to receive their results (i.e. average time per request goes down). As impressive as these benchmarking numbers are, these tests do not represent typical user interaction (i.e. batching full spectrum analytic runs). If done correctly, massive in-memory databases with intensely complex analytics can scale to thousands of users on a single instance (think TCO here), each capable of running their own simulations—change anything, anytime, and simultaneously compare the results of multiple scenarios in seconds.
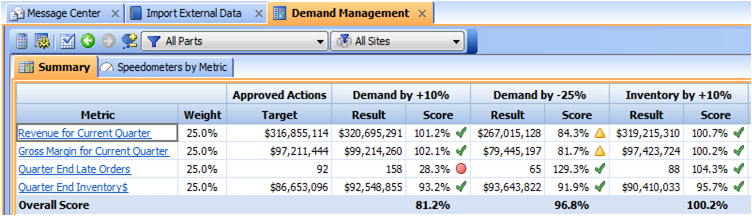
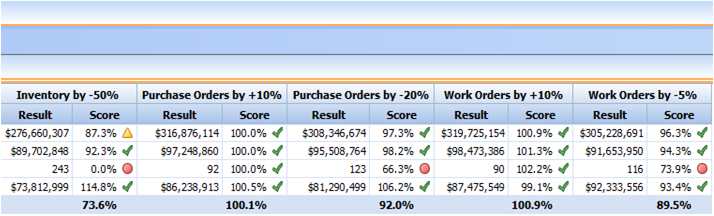
RapidResponse simultaneously measuring eight scenarios for a user using weighted scorecard All this speed and scale becomes valuable when businesses can bring about new and improved processes capable of delivering breakthrough performance improvements. With collaboration gaining traction as the new supply chain optimizer, companies are driving innovation toward this area and testing in-memory databases in new ways. For example, not only is it important to monitor changes in the supply chain and the potential risk/opportunity they create, companies now want to know “who” is impacted, “who” needs to know, and “who” needs to collaborate. While this seems like an obvious value proposition, the science involved in delivering this on a real-time basis is staggering. I’m happy to see SAP draw such attention to the merits of in-memory databases. It serves to validate 25 years of our heritage, our focused research and development, and surely validates the investments made by some of SAP’s largest customers (Honeywell, Jabil, Raytheon, Lockheed Martin, RIM, Nikon, Flextronics, Deere, and many more) to leverage RapidResponse. Whether related to Sales and Operations Planning, Demand Management, Constrained Supply Allocation, Multi-Enterprise Supply Chain Modeling, Clear-to-Build, Inventory Liability Reduction, What-if Simulation, Engineering Change Management, etc., these great companies are experiencing and benefiting from the speed of in-memory technology today. Why wait?
Leave a Reply